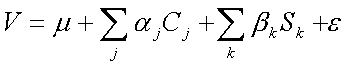Data Science: Similarity Least Squares (SLSTM) + physics + Statistical Design of Experiment (DOE)
A New Paradigm for Analysis and Management of Complexity
![]()
|
Data Science: Similarity Least Squares (SLSTM) + physics + Statistical Design of Experiment (DOE) A New Paradigm for Analysis and Management of Complexity
|
|
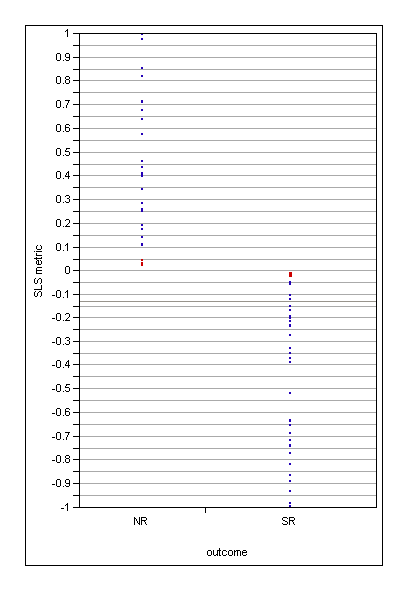
week 4 SLSTM model formula based on preprocessed clinical
variables (ref clinical study) In mathematical terms, the scoring function created by SLSTM can be expressed as follows:
where V is the SLSTM-derived metric used to predict outcome for each patient where high values imply NR*, {C} is a subset of preprocessed clinical variables, Sk is the similarity function between the patient profile (object properties) and the object k containing key combinatorial effects. Recall Similarity can be any viable function of object proximity. The Greek symbols (µ, alpha, ß and e) are parameters optimized for the training data composed of critical patients. Probabilities can be assigned to the scalar scaled scores V by appropriate statistical procedures such as logistic regression.For this data the SLSTM process applied a simple similarity, ie, a Gaussian of weighted Euclidean distance:
. {C} = Z set of clinical variables defining patient profile. EXAMPLEs {Fk} = Z set of profile variables for feature k (super vector) {d} = set of weighting factors determined by SLS™ technology *Thresholds:
|
Copyright of James M Minor, July 4, 2004.
|